Table of Contents
Getting started with CAPRI
Installing CAPRI Stable Release 2 and earlier
CAPRI Stable Release (STAR) 2 and earlier releases are published with a full set of data, i.e. including all the intermediate data required to build the complete database and produce a calibrated baseline. The model with raw data and the consolidated model database are shipped in two compressed archives. For the latest release, STAR 2.8, they are called “STAR_2.8.zip” and “results_2.8.zip” respectively, and with similar naming pattern for other releases. Follow the steps below in order to install CAPRI on your system. Using CAPRI requires extensive knowledge of how the system works. Please look out for CAPRI training courses on the page of upcoming events. The following bare-bone instructions may nevertheless be sufficient to get the system up and technically running.
Attention
CAPRI Stable Release 2 is not very up-to-date. You can, of course, continue to use these versions, but if you want to work with a CAPRI version that includes features developed in the main until May 2024, you should use the version that is used in the CAPRI Course. For downloading the latest 2024 CAPRI version used in the CAPRI course please External Link
1. Ensure that you have Java and GAMS installed on your computer (only required for version until star 2.7)
See system requirements. Note: CAPRI version star 2.8 includes a GAMS version and a java version in the package (STAR_2.8.zip). No installation of gams or java is required.
2. Download the two archives
Click the links to “Code” and “Database” in the table of available CAPRI versions below. We recommend using the latest available release.
3. Extract the files to a local hard drive
- Create an installation folder to hold model source files on your local hard drive such that the path does not contain spaces. Thus, it will not work to install the model in “My Documents” (path containing space) or on a network drive (the access will be too slow). We call this the “CAPRI system folder”. We assume here you created a folder
C:/CAPRI/Start_2_8. - Extract the files of the compressed archive with code, e.g.
STAR_2.8.zipinto the CAPRI system folder. - Extract the files of the compressed archive with data, e.g.
results_2.8.zipinto the subfolderoutput/resultsin the CAPRI system folder.
The resulting directory structure in your CAPRI system folder should look like this afterwards:
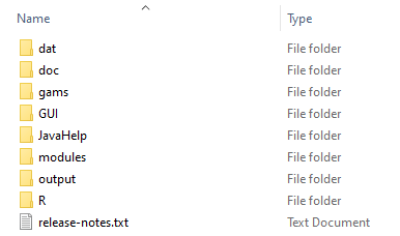
The directory structure inside the folder output/results should look like this:

4. Adjust the settings to your computer
- Go to the subfolder “GUI”, double-click “start_capri.bat”. That should open the graphical user interface (GUI). If not, something is wrong with your Java-installation.
- In the menu settings, choose Edit settings.
- In the first tab: enter your name
- In the second tab: verify that the paths to result and restart folders are set to ../output/results and ../output/restart. The GAMS directory should read ../gams and the data directory should read ../dat.
- In the third tab: enter the complete path to the GAMS executable. Probably it is something like ../GUI/gams_exe/34.3/gams.exe. Also verify that the path to the Scratch directory is ../output/temp. Click the button to “get number of processors”.
- In the fourth tab: do nothing.
- In the final tab: do nothing, or, if you have a programming text editor, enter the path to that editor in the proper field.
- Click “Save in caprinew.ini” and accept the file name suggested for your settings.
- Close the GUI, then start it again (using start_capri.bat), to make it process all your settings.
Download the current release
From 2016, the CAPRI model was made more accessible to the scientific community by the provision of supported stable releases. The stable releases are tagged and “frozen” versions of the model that can be referenced to and that will not change. The bug fixes and other code updates result in new releases with updated revision numbers. The release versions have been subjected to extensive testing, ensuring that all supported features technically work under different hardware/software settings.
The stable release consists of (a) the model code including raw data and (b) the compiled data base including calibrated baselines. The model is really self contained in (a), since all software and raw data needed to compile the data bases and construct the baselines is found there. Albeit (b), the databases, can be derived from (a), doing so is a somewhat complicated process. Therefore, we provide (b) as a shortcut. Furthermore, it turns out that generating (b) may generate slightly different results on different hardware/software combinations, and therefore it is convenient to use a common versioned database release.
The current release and selected previous releases can be downloaded as compressed (zipped) archives using the links in the following table. Note that the item “SVN-tag” only are available to developers with a an account in the SVN database. Information about each release is found in the release notes, Release notes (cumulative) and in each release code base.
System requirements
CAPRI requires that you have a windows computer with Java and GAMS (http://www.gams.com, distribution 32.2 or later is recommended) installed. You need a license for the CONOPT solver. Many tasks in CAPRI utilize parallel computing. It is therefore an advantage if you have a machine that can run many threads in parallel.
Regarding Java: There are some licensing implications when using Oracle's platform. Public updates released after January 2019 will not be available for business, commercial, or production use without a commercial license. Since then the GUI for java can also be executed using a open and free installation of OpenJDK.
Note: From Star 2.8 java is embedded in star2.8.zip. There is no additional installation of java JRE necessary.
Build databases and baselines
The stable releases are shipped with the data needed to make simulations. Advanced users may want to run the data consolidation steps themselves. It can be done using the following steps. Note that this is not needed if you downloaded and installed the pre-compiled database in the steps described above.
Compiling the database from scratch takes a long time. Depending on the hardware you use, it can take up to several days. In order to keep track of all the various settings required for completing all the steps, the release contains a “batch execution file” that instructs the GUI how to carry out a sequence of tasks without intervention of the user. Here is what you need to do:
- In the GUI, choose the menu GUI –> Batch execution
- In the dialogue, choose the file
<gamsdir>/GUI/batchfiles/build_database_and_baseline.txt - Uncheck the option “Only compile the GAMS programs”
- Click “Start batch execution”.
- Wait for the program to finish (hours, days).
- Click “Open HTML report” and verify that all steps were completed without errors (RC=0).
The current batch execution file (STAR 2.7) does not take over the path to your GAMS installation as entered in the settings dialogue during installation, but you will have to open the text file and enter the appropriate path manually.
Release notes (cumulative)
STAR 2.8
Main update relates to the GUI folder by embedded java/gams version, some more minor issues below:
- empty folder problem with ziped files avoided by includeing void.gdx files in gams/temp and userScen in gams/temp - scenario for import ban included - BREXIT mode standard setting in capri_gui_definition.xml - Edits to avoid non unique names in controls in capri_gui_definition.xml - Inflation_and_trend_interpolation.gms adjusted that also comi prices can be simulated - batch file adjusted in FAO split into two separate tasks as in the trunk to improve stability
STAR 2.7
Most importantly, the dairy market should now be linked with the supply models, and the new feed version is used by default. Other minor issues below:
- Priors missing in GHG emission trend estimation now exist (again?)
- The fallback structure for missing nutrient balance data in West Balkan and Turkey taken over from Trunk.
- Import surge of cheese in market baseline prevented by adjusted bounds widening. This problem does not seem to exist in trunk.
- FAOSTAT bug fixed (exportGUI task failed)
STAR 2.6
Update of the graphical user interface (GUI) to allow the use of the policy editor.
STAR 2.5
Several modifications of the premium payments, for the Basic Payment Schemes, where the results were found not to fit observations.
STAR 2.4
This maintenance release addresses …
- Pillar 1 payments of the CAP were missing for “new” member states when running CAP 2014-2020 for a year before 2020.
- Several minor tweaks and fixes.
STAR 2.3
This maintenance release addresses stability of feeding, reporting for fertilizers, and also includes some cleaning up of code:
- The feed distribution was revised to become more stable under repeated starts (P. Witzke)
- Several options were removed from the GUI with respect to the estimation of GHG emission trends
- A large pack of updates to the GHG emission estimations were imported from the development branch ClipByFood
- The inner fertilizer allocation model can be turned OFF in simulations (on by default)
- The GUI now reports a decomposition of the NUTNED_ equation, accessible under the theme “Fertilization”
- Some items were excluded from checks in COCO to make the program run through with GAMS 25.0 and 25.1
- The legacy data set on ghg emissions from EDGAR was removed.
STAR 2.2
This maintenance release resolves several important calibration issues.
- The market model did not calibrate properly due to an inconsistently included “BREXIT” policy
- The supply models did not calibrate properly due to missing parameters for manure trade
- The stability tests did not give true results due to an inconsistent use of results_in and results_out, essentially mixing fertilizer parameters of two runs
- Several minor bug fixes, e.g. in linking supply and demand and scaling of NMIN
- A final overhaul of feeding is still due in Maintenance Release 2.3.
STAR 2.1
This maintenance release implements the revised treatment of fertilizers and feed. For fertilizers, a bi-level programming approach has been implemented, where the flows of fertilizers are modelled as a Bayesian estimator ensuring an interior solution that is “close to” the calibrated flows when simulating and close to a prior distribution when calibrating. For feed, the distribution of feeding stuffs to animals was revised to improve plausibility and stability, but without principal changes of the way the model works.
In addition to the feed and fertilizer modifications, the following bugs or minor issues were addressed:
- Changing the order of work steps and tasks in the GUI to reflect the order in which the steps can be carried out (e.g. FAOSTAT first)
- An issue with price experiments in Threads-mode was resolved
- Start at an infrastructure to report the results of the fertilizer allocation to DATAOUT (reports/fert_dist_results.gms)
- Relaxing the winter cover requirement in one Finnish region to avoid infeasibility in baselines.
- The income computations for EAA had inconsistent prices for FODDER, so that the regional farms had costs <> revenues for fodder, which should not be possible.
- The Dual Analysis of the supply models had not updated versions of some constraints, so that there were an “unexplained rest”. (sugar beet and greening restrictions)
Finally, the testing routines were augmented and slightly revised, to include individual testing of simulations with supply and market models standalone.
STAR 2.0
This new series of releases contains two key modifications:
- It calibrates to the CAP post 2014 instead of the old MTR scenario. This required adding the first-order conditions of the greening restrictions in the PMP algorithm, which was not trivial.
- It includes the possibility to set BREXIT ON when building the database. This allows the user to build a model where the UK is a separate market model region with bilateral trade instruments with the EU. This is now the standard setting, albeit it implements free trade between UK and EU27.
Some modifications that were scheduled for this release were not included, because they were not sufficiently stable in testing at the key date for the release. In particular, the following components are essentially unchanged from STAR 1.3 but scheduled for inclusion in a subsequent release.
- Revision of the fertilizer distribution. This was found to be numerically unstable in STAR 1.0, and is still so as testing revealed.
- Revision of the feed distribution to give more stable results and a more plausible allocation of feeding stuffs.
Finally, this release has some known issues in addition to the points mentioned above:
- New Norwegian data was made available but not in time to complete the testing phase.
- There are occasional problems to reproduce the baseline in 2030 when market and supply are allowed to interact. The precise circumstances causing this to happen are still unclear.
STAR 1.3
A maintenance release addressing the following issue in STAR 1.2:
- Including the most recent Graphical User Interface (GUI)
- A bug with the Basic Payment Scheme in Greece led to missing payments in several Greek regions.
- Changing the way the grassland maintenance requirement works in Greening (lower bound on grass land)
- Modified reporting for EU28
- Modified report tables for the GUI
It was observed that when the GUI batch execution file “build_database_and_baseline.txt” was executed with this model version, the baseline calibration of the market model sometimes failed.In that case, a manual re-start of that task directly from the GUI using the default settings worked. Furthermore, it was observed that the baseline reproduction run (i.e. calibrating to mtr_rd_cal and then simulating mtr_rd_ref) resulted in small changes in some of the “new” member states, in particular Serbia.
STAR 1.2
A maintenance release addressing two minor problems encountered in STAR 1.1.
- A bug fix in the rural development policy logic (gams/policy/rd_logic.gms). The bug may have caused problems when building a regionalized database if a particular folder (results_out/capmod) was missing.
- A bug in the batch execution file “build_database_and_baseline.txt” that prevented the farm type databases from being built.
STAR 1.1
This is a maintenance release addressing some issues that surfaced since STAR 1.0 was published.
- The scaling of Japanese prices was wrong, leading to biased results in the market model
- Several issues relating to the implementation of the second pillar payments, causing them to be missing or wrong in CAPMOD (simulation) and also CAPREG (regional database)
- Renaming all the standard scenario files in the folder pol_input/CAP_AFTER_2014, so that the (CAPMOD) result file names become shorter and more instructive
- A randomly appearing issue with farm type trends. GAMS had problems deleting grid computing handles under full system load (parallel computing)
- A bug in the user interface that caused the batch execution (e.g. build_database_and_baseline.txt) to launch Turkey (only!) in the wrong way
- Setting the default number of processors in the “build_database_and_baseline.txt” batch to “4”, so that it is fairly safe to start without any modification.
STAR 1.0
This release attempts to provide a CAPRI model where a wide selection of tasks from baseline construction to simulation can be carried out. With other versions of CAPRI, it has been a general feature that when some tasks were maintained, others ceased to work, so that there were multiple model versions where some problems had been resolved but where not everything worked properly.
Since it is utopic to aspire that all mechanisms ever built into CAPRI would work simultaneously, a selection of “supported features” was created. Features of the model that are not “supported” are simply not tested, and so they may or may not perform as intended. The list of supported features is documented in programmatic form in the GUI batch execution file “supported_features.txt”.
Some features that should be supported still fail to work properly. In particular, we note that the following technical problems persist:
- “Generate GAMS child processes on different threads”, causing many procedures in the model to run in parallel as gams child processes if set ON, is not entirely stable. Recommendation is to keep OFF for reproducibility.
- “Dampening of high activity level elasticities” must still be kept OFF. It is unclear whether this feature will survive or rather be replaced by some general adaptation of elasticities for long run experiments in combination with a revised calibration procedure
- Numerical instability of the calibration of fertilizer distribution among crops. Repeated runs do not give identical results.
- Numerical instability of the calibration of animal feed to various animals. Repeated runs do not give identical results.
- Occasional failure of task “Generate farm type trends” for random regions. Remedy: Re-run “Build regional time series” and “Build regional database” for that country, for nuts2 and farm types, and redo all tasks from “Build global database” onwards.
The release has not been systematically tested from a content point of view. Nevertheless, release candidates have been used in a few applications, where some issues have surfaced. In particular, the distribution of rural development funds needs to be revised. Such revision has partially been done already in various projects, but the modifications need to be consolidated and integrated into a maintenance release. Similar improvements have accumulated in the areas of market model tariff data and greenhouse gas emissions, also foreseen to be integrated in a future maintenance release, after thorough testing.